Overview
Omnibus modelling combines primary predictive microbiology models with secondary covariate relationships in a single nonlinear mixed-effects model.
In predmicror, the omnibus helpers are designed to reuse
the primary and secondary models already available in the package. This
means that the same primary models used by fit_growth() and
fit_inactivation() can also be used in grouped omnibus
models.
The main workflow is:
- choose a primary growth or inactivation model;
- decide which primary-model parameters should depend on covariates;
- define the grouping variable for random effects;
- fit the model with
fit_omnibus_growth()orfit_omnibus_inactivation(); - inspect fitted values, residuals, metrics, and validation results.
Omnibus models are especially useful when observations are grouped by experimental condition, strain, replicate, batch, study, or treatment.
Omnibus inactivation model
The simplest omnibus inactivation workflow uses a primary inactivation model and allows one of its parameters to depend on an environmental covariate.
In this example, the primary model is WeibullM(). The
parameter sigma is modelled as a function of temperature,
while Y0 and alpha are estimated as
intercept-only fixed effects. The grouping variable is
Condition.
set.seed(1)
inact_data <- do.call(rbind, lapply(1:4, function(g) {
Time <- c(1, 2, 4, 6, 8, 10)
Temp <- 55 + g
sigma <- 5 + 0.4 * g
data.frame(
Condition = g,
Time = Time,
Temp = Temp,
logN = WeibullM(Time, Y0 = 7, sigma = sigma, alpha = 1.1) +
rnorm(length(Time), 0, 0.03)
)
}))
head(inact_data)
#> Condition Time Temp logN
#> 1 1 1 56 6.620974
#> 2 1 2 56 6.233335
#> 3 1 4 56 5.319739
#> 4 1 6 56 4.462332
#> 5 1 8 56 3.461902
#> 6 1 10 56 2.440331
inact_fit <- fit_omnibus_inactivation(
data = inact_data,
primary = "WeibullM",
time = "Time",
response = "logN",
group = "Condition",
secondary = list(
sigma = ~ Temp
),
random = Y0 ~ 1,
start = c(
Y0 = 7,
sigma = 1,
sigma.Temp = 0.08,
alpha = 1
)
)
inact_fit
#> predmicror omnibus fit
#> type: inactivation
#> primary: WeibullM
#> response: logN (log10N)
#> group: Condition
#> formula: logN ~ WeibullM(Time, Y0, sigma, alpha)
#>
#> Nonlinear mixed-effects model fit by maximum likelihood
#> Model: logN ~ WeibullM(Time, Y0, sigma, alpha)
#> Data: structure(list(Condition = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 3L, 3L, 3L, 3L, 3L, 3L, 2L, 2L, 2L, 2L, 2L, 2L, 4L, 4L, 4L, 4L, 4L, 4L), levels = c("1", "3", "2", "4"), class = c("ordered", "factor")), Time = c(1, 2, 4, 6, 8, 10, 1, 2, 4, 6, 8, 10, 1, 2, 4, 6, 8, 10, 1, 2, 4, 6, 8, 10), Temp = c(56, 56, 56, 56, 56, 56, 57, 57, 57, 57, 57, 57, 58, 58, 58, 58, 58, 58, 59, 59, 59, 59, 59, 59), logN = c(6.62097416702643, 6.23333463512458, 5.31973851370095, 4.46233231137142, 3.46190216515927, 2.44033100640526, 6.68162236376677, 6.30834752659853, 5.48720489842949, 4.60076476835948, 3.76557971644166, 2.81946728291791, 6.67191681320917, 6.2702470472557, 5.61190762362015, 4.77763845418162, 3.95173288068617, 3.13262114209126, 6.73575671288993, 6.39858936905395, 5.7002257519511, 4.95006102960119, 4.15701372323355, 3.30353668937129)), row.names = c(NA, -24L), class = c("nfnGroupedData", "nfGroupedData", "groupedData", "data.frame"), formula = logN ~ Time | Condition, FUN = function (x) max(x, na.rm = TRUE), order.groups = TRUE)
#> Log-likelihood: 52.4009
#> Fixed: list(Y0 = Y0 ~ 1, sigma = sigma ~ Temp, alpha = alpha ~ 1)
#> Y0 sigma.(Intercept) sigma.Temp alpha
#> 6.9784233 -16.6828585 0.3958743 1.1210657
#>
#> Random effects:
#> Formula: Y0 ~ 1 | Condition
#> Y0 Residual
#> StdDev: 2.519748e-06 0.0272607
#>
#> Number of Observations: 24
#> Number of Groups: 4The fitted object can be inspected with the same lightweight
diagnostic helpers used elsewhere in predmicror.
head(predmicror_augment(inact_fit))
#> Condition Time Temp logN .fitted .resid .model
#> 1 1 1 56 6.620974 6.636875 -0.015900789 WeibullM
#> 2 1 2 56 6.233335 6.235530 -0.002195110 WeibullM
#> 3 1 4 56 5.319739 5.362573 -0.042834948 WeibullM
#> 4 1 6 56 4.462332 4.432702 0.029630411 WeibullM
#> 5 1 8 56 3.461902 3.463827 -0.001925154 WeibullM
#> 6 1 10 56 2.440331 2.464877 -0.024545994 WeibullM
#> .type
#> 1 omnibus_inactivation
#> 2 omnibus_inactivation
#> 3 omnibus_inactivation
#> 4 omnibus_inactivation
#> 5 omnibus_inactivation
#> 6 omnibus_inactivation
fit_metrics(inact_fit)
#> model type response response_scale n p SSE
#> 1 WeibullM omnibus_inactivation logN log10N 24 4 0.0178355
#> RMSE MAE bias RSE R2 adj_R2 logLik
#> 1 0.0272607 0.02180912 4.219951e-09 0.0298626 0.9995866 0.9994995 52.4009
#> AIC BIC converged
#> 1 -92.80179 -85.73347 TRUE
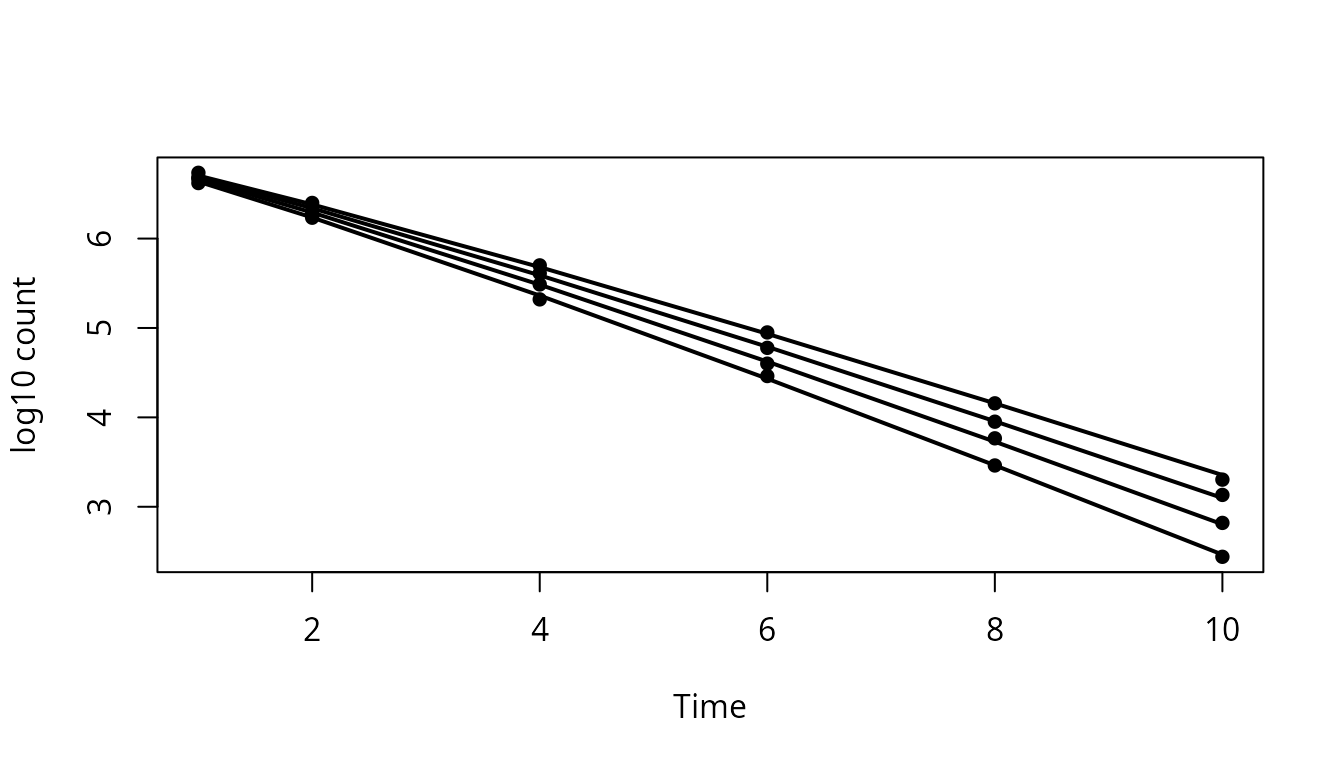
aug_inact <- predmicror_augment(inact_fit)
plot(aug_inact$Time, aug_inact$logN,
pch = 16,
xlab = "Time",
ylab = "log10 count"
)
for (g in unique(aug_inact$Condition)) {
z <- aug_inact[aug_inact$Condition == g, ]
z <- z[order(z$Time), ]
lines(z$Time, z$.fitted, lwd = 2)
}
Omnibus growth model
The same structure can be used for grouped growth data. Here the
primary model is HuangNLM(), and the maximum specific
growth rate MUmax is described as a function of
temperature.
set.seed(1)
growth_data <- do.call(rbind, lapply(1:4, function(g) {
Time <- c(0, 1, 2, 3, 4, 5, 6)
Temp <- 20 + g
MUmax <- 0.6 + 0.04 * g
data.frame(
Condition = g,
Time = Time,
Temp = Temp,
lnN = HuangNLM(Time, Y0 = 2, Ymax = 8, MUmax = MUmax) +
rnorm(length(Time), 0, 0.02)
)
}))
head(growth_data)
#> Condition Time Temp lnN
#> 1 1 0 21 1.987471
#> 2 1 1 21 2.641453
#> 3 1 2 21 3.256872
#> 4 1 3 21 3.937580
#> 5 1 4 21 4.537433
#> 6 1 5 21 5.126897
growth_fit <- fit_omnibus_growth(
data = growth_data,
primary = "HuangNLM",
time = "Time",
response = "lnN",
group = "Condition",
secondary = list(
MUmax = ~ Temp
),
random = Y0 ~ 1,
start = c(
Y0 = 2,
Ymax = 8,
MUmax = 0.1,
MUmax.Temp = 0.025
)
)
growth_fit
#> predmicror omnibus fit
#> type: growth
#> primary: HuangNLM
#> response: lnN (lnN)
#> group: Condition
#> formula: lnN ~ HuangNLM(Time, Y0, Ymax, MUmax)
#>
#> Nonlinear mixed-effects model fit by maximum likelihood
#> Model: lnN ~ HuangNLM(Time, Y0, Ymax, MUmax)
#> Data: structure(list(Condition = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 4L, 4L), levels = c("1", "2", "3", "4"), class = c("ordered", "factor")), Time = c(0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6), Temp = c(21, 21, 21, 21, 21, 21, 21, 22, 22, 22, 22, 22, 22, 22, 23, 23, 23, 23, 23, 23, 23, 24, 24, 24, 24, 24, 24, 24), lnN = c(1.98747092378515, 2.64145317788601, 3.25687162671724, 3.93758000587105, 4.53743344067042, 5.12689720003012, 5.74282755165066, 2.01476649410258, 2.68910453450559, 3.3467389327674, 4.05378727999164, 4.69325099952427, 5.31824053768023, 5.90106304394057, 2.02249861836286, 2.71649105892164, 3.43172458597324, 4.16004039778447, 4.85559114985202, 5.52731704819102, 6.16956950824529, 2.01564272601462, 2.75867376798095, 3.47139727772465, 4.27087456686563, 4.99071587286447, 5.69403475902795, 6.31996023037454)), row.names = c(NA, -28L), class = c("nfnGroupedData", "nfGroupedData", "groupedData", "data.frame"), formula = lnN ~ Time | Condition, FUN = function (x) max(x, na.rm = TRUE), order.groups = TRUE)
#> Log-likelihood: 73.33818
#> Fixed: list(Y0 = Y0 ~ 1, Ymax = Ymax ~ 1, MUmax = MUmax ~ Temp)
#> Y0 Ymax MUmax.(Intercept) MUmax.Temp
#> 2.00399031 7.85516981 -0.19926002 0.04003597
#>
#> Random effects:
#> Formula: Y0 ~ 1 | Condition
#> Y0 Residual
#> StdDev: 2.060366e-06 0.01762989
#>
#> Number of Observations: 28
#> Number of Groups: 4
head(predmicror_augment(growth_fit))
#> Condition Time Temp lnN .fitted .resid .model .type
#> 1 1 0 21 1.987471 2.003990 -0.016519389 HuangNLM omnibus_growth
#> 2 1 1 21 2.641453 2.642902 -0.001448883 HuangNLM omnibus_growth
#> 3 1 2 21 3.256872 3.279509 -0.022637046 HuangNLM omnibus_growth
#> 4 1 3 21 3.937580 3.911784 0.025795919 HuangNLM omnibus_growth
#> 5 1 4 21 4.537433 4.535999 0.001434902 HuangNLM omnibus_growth
#> 6 1 5 21 5.126897 5.145472 -0.018574974 HuangNLM omnibus_growth
fit_metrics(growth_fit)
#> model type response response_scale n p SSE RMSE
#> 1 HuangNLM omnibus_growth lnN lnN 28 4 0.008702767 0.01762989
#> MAE bias RSE R2 adj_R2 logLik AIC
#> 1 0.0139971 4.801674e-07 0.01904246 0.9998314 0.9998021 73.33818 -134.6764
#> BIC converged
#> 1 -126.6831 TRUE
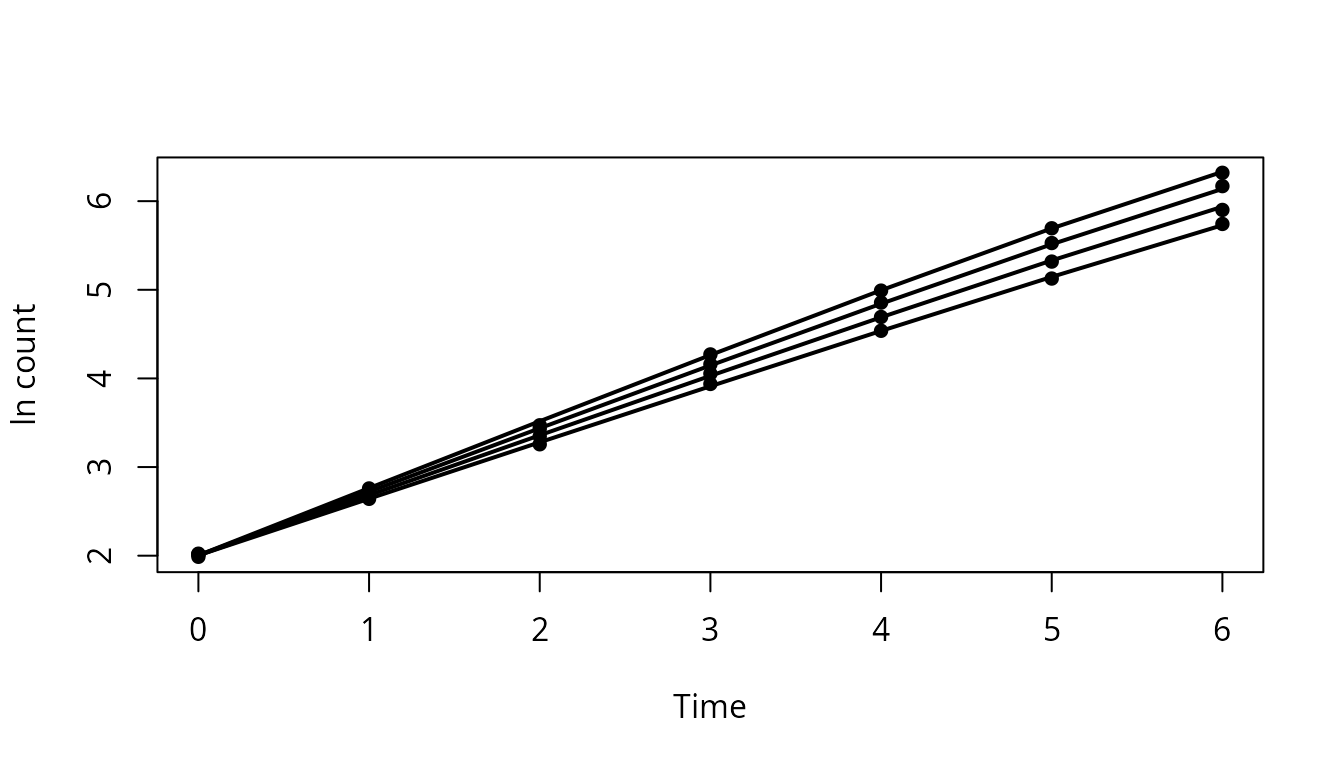
aug_growth <- predmicror_augment(growth_fit)
plot(aug_growth$Time, aug_growth$lnN,
pch = 16,
xlab = "Time",
ylab = "ln count"
)
for (g in unique(aug_growth$Condition)) {
z <- aug_growth[aug_growth$Condition == g, ]
z <- z[order(z$Time), ]
lines(z$Time, z$.fitted, lwd = 2)
}
Using parameterised secondary models
Omnibus models can also use secondary models already implemented in
predmicror. This is useful when a primary-model parameter
should follow a mechanistic or cardinal-type relationship instead of a
simple linear formula.
In the example below, the primary model is again
HuangNLM(), but MUmax is now described using
the cardinal temperature model CMTI().
Because CMTI() returns a square-root growth-rate scale,
transform = "square" is used to convert the secondary-model
output to the growth-rate scale used by MUmax.
set.seed(2)
cardinal_growth_data <- do.call(rbind, lapply(1:5, function(g) {
Time <- c(0, 1, 2, 3, 4, 5, 6)
Temp <- 12 + 3 * g
MUmax <- CMTI(Temp, Tmax = 45, Tmin = 5, MUopt = 0.9, Topt = 30)^2
data.frame(
Condition = g,
Time = Time,
Temp = Temp,
lnN = HuangNLM(Time, Y0 = 2, Ymax = 8, MUmax = MUmax) +
rnorm(length(Time), 0, 0.02)
)
}))
head(cardinal_growth_data)
#> Condition Time Temp lnN
#> 1 1 0 15 1.982062
#> 2 1 1 15 2.362623
#> 3 1 2 15 2.749147
#> 4 1 3 15 3.052584
#> 5 1 4 15 3.430443
#> 6 1 5 15 3.790209
cardinal_growth_fit <- fit_omnibus_growth(
data = cardinal_growth_data,
primary = "HuangNLM",
time = "Time",
response = "lnN",
group = "Condition",
secondary = list(
MUmax = omnibus_secondary("CMTI", x = "Temp", transform = "square")
),
random = Y0 ~ 1,
start = c(
Y0 = 2,
Ymax = 8,
Tmax = 45,
Tmin = 5,
MUopt = 0.9,
Topt = 30
)
)
cardinal_growth_fit
#> predmicror omnibus fit
#> type: growth
#> primary: HuangNLM
#> response: lnN (lnN)
#> group: Condition
#> formula: lnN ~ HuangNLM(Time, Y0, Ymax, I((CMTI(Temp, Tmax, Tmin, MUopt, Topt))^2))
#>
#> Nonlinear mixed-effects model fit by maximum likelihood
#> Model: lnN ~ HuangNLM(Time, Y0, Ymax, I((CMTI(Temp, Tmax, Tmin, MUopt, Topt))^2))
#> Data: structure(list(Condition = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L), levels = c("1", "2", "3", "4", "5"), class = c("ordered", "factor")), Time = c(0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6, 0, 1, 2, 3, 4, 5, 6), Temp = c(15, 15, 15, 15, 15, 15, 15, 18, 18, 18, 18, 18, 18, 18, 21, 21, 21, 21, 21, 21, 21, 24, 24, 24, 24, 24, 24, 24, 27, 27, 27, 27, 27, 27, 27 ), lnN = c(1.9820617090675, 2.36262344391347, 2.74914663772612, 3.05258368866915, 3.4304433561042, 3.79020926889497, 4.1553227681562, 1.99520603951656, 2.55947985436003, 3.03565098609, 3.56348390303133, 4.08824833456485, 4.56890642276389, 5.0553779465349, 2.03564457920617, 2.62166940860562, 3.35111298615531, 3.9955718804389, 4.66811960427567, 5.29388459168275, 5.93600507396063, 1.97600148360712, 2.81986937220297, 3.61167933835148, 4.34944574577588, 5.06053617417389, 5.84534237095992, 6.48524344985914, 2.01584406540599, 2.87355374189087, 3.74556894324385, 4.5891091351393, 5.43087451007167, 6.17575286805776, 6.83375095275577 )), row.names = c(NA, -35L), class = c("nfnGroupedData", "nfGroupedData", "groupedData", "data.frame"), formula = lnN ~ Time | Condition, FUN = function (x) max(x, na.rm = TRUE), order.groups = TRUE)
#> Log-likelihood: 84.60831
#> Fixed: list(Y0 = Y0 ~ 1, Ymax = Ymax ~ 1, Tmax = Tmax ~ 1, Tmin = Tmin ~ 1, MUopt = MUopt ~ 1, Topt = Topt ~ 1)
#> Y0 Ymax Tmax Tmin MUopt Topt
#> 2.0052472 7.9275590 45.6335490 5.2509226 0.9038282 30.1598866
#>
#> Random effects:
#> Formula: Y0 ~ 1 | Condition
#> Y0 Residual
#> StdDev: 5.581873e-07 0.02157287
#>
#> Number of Observations: 35
#> Number of Groups: 5
head(predmicror_augment(cardinal_growth_fit))
#> Condition Time Temp lnN .fitted .resid .model .type
#> 1 1 0 15 1.982062 2.005247 -0.0231854618 HuangNLM omnibus_growth
#> 2 1 1 15 2.362623 2.363562 -0.0009389208 HuangNLM omnibus_growth
#> 3 1 2 15 2.749147 2.721379 0.0277677521 HuangNLM omnibus_growth
#> 4 1 3 15 3.052584 3.078483 -0.0258997709 HuangNLM omnibus_growth
#> 5 1 4 15 3.430443 3.434573 -0.0041297345 HuangNLM omnibus_growth
#> 6 1 5 15 3.790209 3.789219 0.0009904124 HuangNLM omnibus_growth
fit_metrics(cardinal_growth_fit)
#> model type response response_scale n p SSE RMSE
#> 1 HuangNLM omnibus_growth lnN lnN 35 6 0.01628861 0.02157287
#> MAE bias RSE R2 adj_R2 logLik AIC
#> 1 0.01615511 -9.471944e-07 0.02369971 0.9997561 0.9997038 84.60831 -153.2166
#> BIC converged
#> 1 -140.7738 TRUE
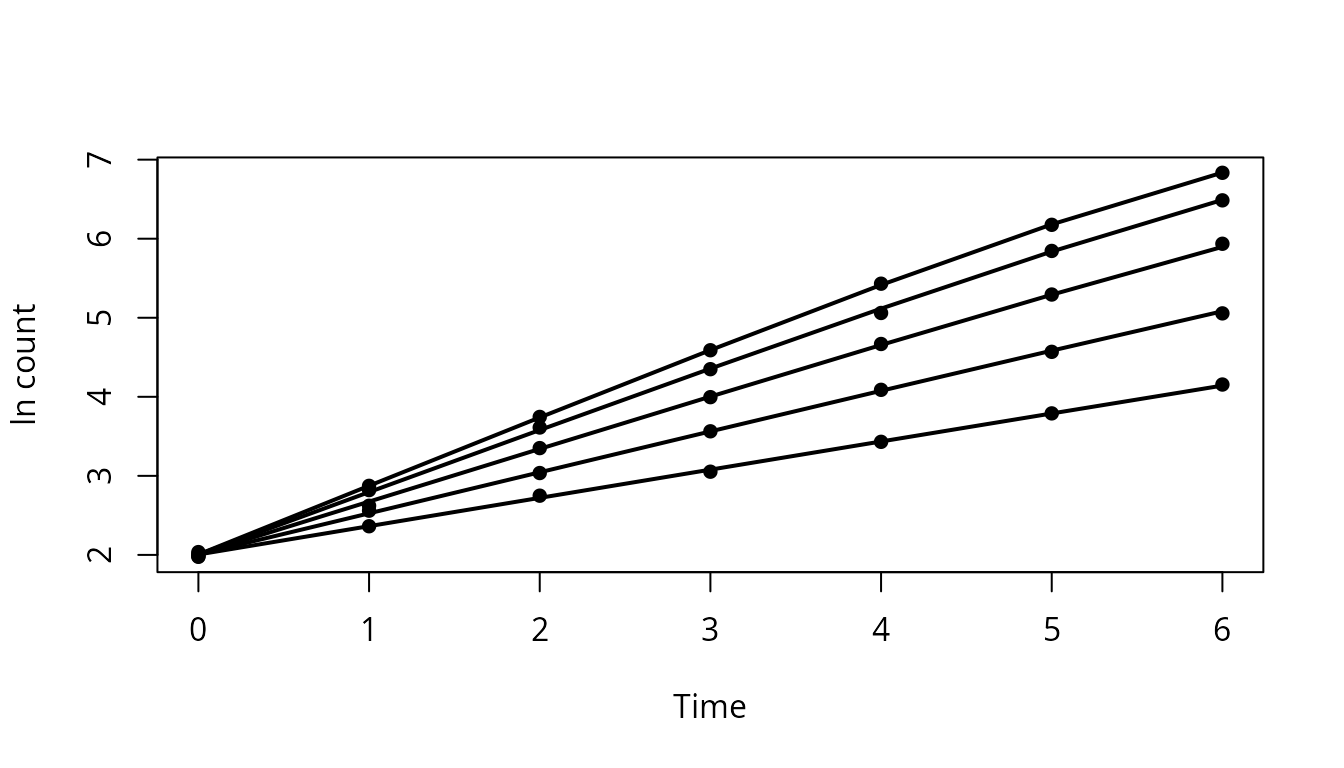
aug_cardinal <- predmicror_augment(cardinal_growth_fit)
plot(aug_cardinal$Time, aug_cardinal$lnN,
pch = 16,
xlab = "Time",
ylab = "ln count"
)
for (g in unique(aug_cardinal$Condition)) {
z <- aug_cardinal[aug_cardinal$Condition == g, ]
z <- z[order(z$Time), ]
lines(z$Time, z$.fitted, lwd = 2)
}
Validation metrics
Predictive microbiology studies often use bias and accuracy factors to summarise external validation performance.
observed <- c(7, 6, 5)
predicted <- c(7.1, 5.9, 5.2)
bias_factor(observed, predicted)
#> [1] 1.012274
accuracy_factor(observed, predicted)
#> [1] 1.02368A leave-one-condition-out validation workflow can be run with
validate_omnibus_leave_one_out(). This refits the model
after removing one group and predicts the left-out observations at the
population level.
loo <- validate_omnibus_leave_one_out(
object = inact_fit,
group_value = 4,
level = 0
)
loo$bias_factor
#> [1] 1.002517
loo$accuracy_factor
#> [1] 1.007128
head(loo$data)
#> Condition Time Temp logN .predicted .resid
#> 19 4 1 59 6.735757 6.695269 0.040488052
#> 20 4 2 59 6.398589 6.376008 0.022581383
#> 21 4 4 59 5.700226 5.682550 0.017675710
#> 22 4 6 59 4.950061 4.944645 0.005416109
#> 23 4 8 59 4.157014 4.176308 -0.019294059
#> 24 4 10 59 3.303537 3.384518 -0.080981434Practical notes
Omnibus models are more flexible than separate primary-model fits, but they require more care.
Good practice includes:
- checking the response scale expected by the selected primary model;
- starting with a simple random-effects structure;
- estimating only parameters supported by the available data;
- using sensible starting values;
- comparing formula-based secondary relationships with parameterised secondary models;
- validating predictions on held-out conditions when possible.
Formula-based secondary relationships are useful for exploratory
modelling, for example MUmax ~ Temp or
sigma ~ Temp. Parameterised secondary relationships are
useful when an established secondary model is available in
predmicror, such as CMTI(),
CMAW(), CMPH(), or CMInh().